纺织学报 ›› 2023, Vol. 44 ›› Issue (07): 192-198.doi: 10.13475/j.fzxb.20220508401
袁甜甜1, 王鑫1, 罗炜豪1, 梅琛楠1, 韦京艳1, 钟跃崎1,2( )
)
YUAN Tiantian1, WANG Xin1, LUO Weihao1, MEI Chennan1, WEI Jingyan1, ZHONG Yueqi1,2()
摘要:
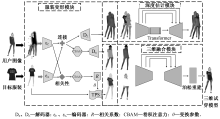
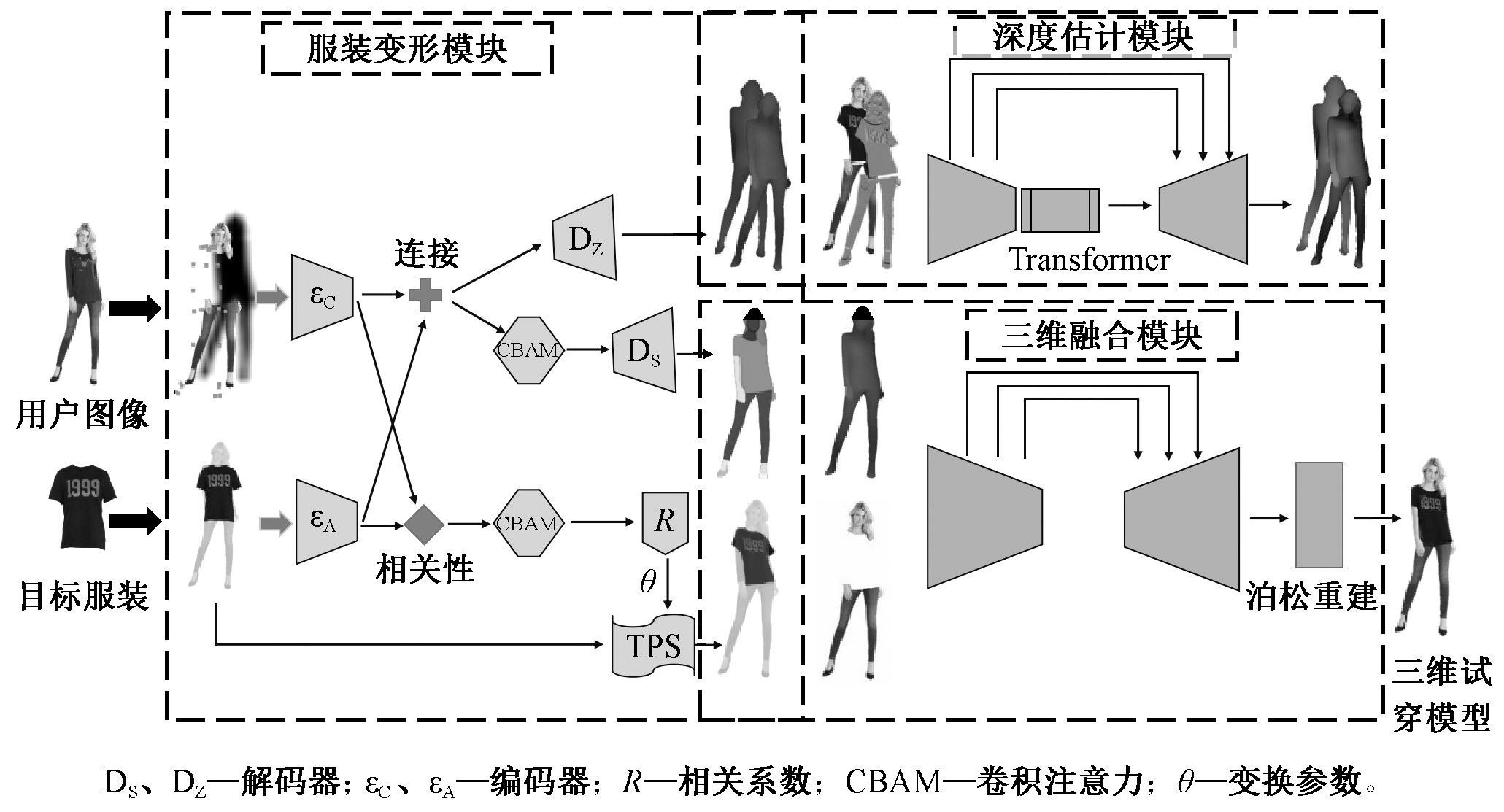
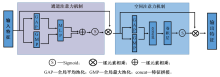
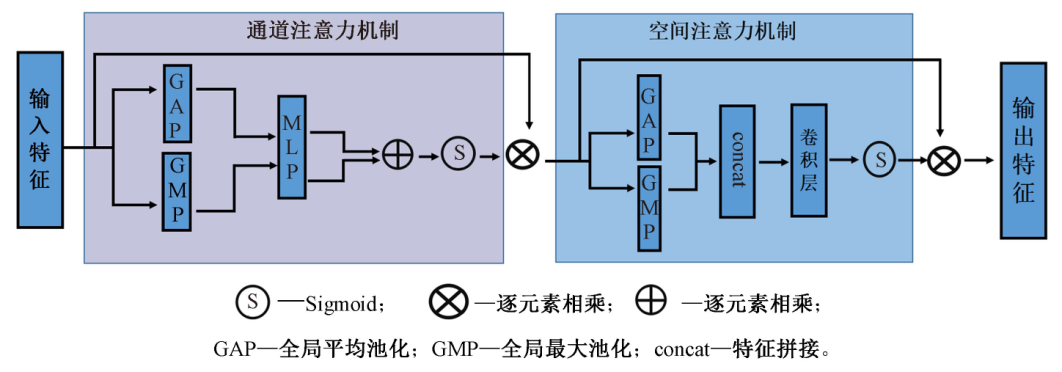
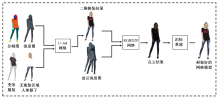
针对三维虚拟试衣网络中易出现的三维人体模型边缘模糊,服装变形严重且存在伪影等问题,设计了三阶段深度神经网络,在第1阶段引入卷积注意力机制,第2阶段采用Resnet和视觉转换器结构结合的编码器-解码器结构,第3阶段通过融合服装变形信息和深度估计信息实现三维虚拟试衣。定量实验结果表明:图像质量评价指标结构相似度提升了0.015 7,峰值信噪比提升了0.113 2;人体模型的深度估计值的绝对相对误差降低了0.037,平方相对误差降低了0.014。定性实验结果表明:卷积注意力机制能够引导网络关注图像细节,保留复杂纹理,约束服装的过度形变,并且有效处理三维人体模型黏连问题。定量和定性分析结果均可表明,该方法能够更加精准地实现预测三维虚拟试衣结果。
中图分类号:
| [1] | HAN X T, WU Z X, WU Z, et al. Viton: an image-based virtual try-on network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2018: 7543-7552. |
| [2] | WANG B C, ZHENG H B, LIANG X D, et al. Toward characteristic-preserving image-based virtual try-on network[C]// Proceedings of the European Conference on Computer Vision (ECCV). Berlin:Springer-Verlag, 2018: 589-604. |
| [3] | GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J]. Communications of the ACM, 2014, 27(2): 2672-2680. |
| [4] | HONDA S. Viton-gan: virtual try-on image generator trained with adversarial loss[C]// Eurographics on Computer Vision and Pattern Recognition. Genova: Computer Graphics Forum, 2019:9-10. |
| [5] | CHOI S, PARK S, LEE M, et al. Viton-hd: high-resolution virtual try-on via misalignment-aware normalization[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2021: 14131-14140. |
| [6] | LOPER M, MAHMOOD N, ROMERO J, et al. Smpl: a skinned multi-person linear model[J]. ACM Transactions on Graphics, 2015, 34(6): 1-16. |
| [7] | KANAZAWA A, BLACK M J, JACOBS D W, et al. End-to-end recovery of human shape and pose[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2018: 7122-7131. |
| [8] | ZHU H, ZUO X X, WANG S, et al. Detailed human shape estimation from a single image by hierarchical mesh deformation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2019: 4491-4500. |
| [9] | SAITO S, HUANG Z, NATSUME R, et al. Pifu: pixel-aligned implicit function for high-resolution clothed human digitization[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Los Alamitos: IEEE Computer Society, 2019: 2304-2314. |
| [10] | HE T, COLLOMOSSE J, JIN H L, et al. Geo-pifu: geometry and pixel aligned implicit functions for single-view human reconstruction[J]. Advances in Neural Information Processing Systems, 2020, 33: 9276-9287. |
| [11] | HUANG Z, XU Y L, LASSNER C, et al. Arch: animatable reconstruction of clothed humans[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2020: 3093-3102. |
| [12] | EFENDIEV Y, LEUNG W T, LIN G, et al. Hei-human: a hybrid explicit-implicit learning for multiscale problems[C]// 4th Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Berlin:Springer-Verlag, 2021:251-262. |
| [13] | HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2018: 7132-7141. |
| [14] | FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Communications Society, 2019: 3146-3154. |
| [15] | WOO S, PARK J, LEE J Y, et al. Cbam: convolutional block attention module[C]// Proceedings of the European Conference on Computer vision (ECCV). Berlin:Springer-Verlag, 2018: 3-19. |
| [16] | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2017: 5998-6008. |
| [17] | ZHAO F W, XIE Z Y, KAMPFFMEYER M, et al. M3D-VTON: a monocular-to-3D virtual try-on network[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. New York: IEEE Communications Society, 2021: 13239-13249. |
| [18] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [19] |
HUYNH-THU Q, GHANBARI M. Scope of validity of PSNR in image/video quality assessment[J]. Electronics Letters, 2008, 44(13): 800-801.
doi: 10.1049/el:20080522 |
| [1] | 付晗, 胡峰, 龚杰, 余联庆. 面向织物疵点检测的缺陷重构方法[J]. 纺织学报, 2023, 44(07): 103-109. |
| [2] | 叶勤文, 王朝晖, 黄荣, 刘欢欢, 万思邦. 虚拟服装迁移在个性化服装定制中的应用[J]. 纺织学报, 2023, 44(06): 183-190. |
| [3] | 陈佳, 杨聪聪, 刘军平, 何儒汉, 梁金星. 手绘草图到服装图像的跨域生成[J]. 纺织学报, 2023, 44(01): 171-178. |
| [4] | 顾梅花, 刘杰, 李立瑶, 崔琳. 结合特征学习与注意力机制的服装图像分割[J]. 纺织学报, 2022, 43(11): 163-171. |
| [5] | 鲁虹, 宋佳怡, 李圆圆, 滕峻峰. 基于合体两片袖的内旋造型结构设计[J]. 纺织学报, 2022, 43(08): 140-146. |
| [6] | 王春茹, 袁月, 曹晓梦, 范依琳, 钟安华. 立领结构参数对服装造型的影响[J]. 纺织学报, 2022, 43(03): 153-159. |
| [7] | 张益洁, 李涛, 吕叶馨, 杜磊, 邹奉元. 服装松量设计及表征模型构建研究进展[J]. 纺织学报, 2021, 42(04): 184-190. |
| [8] | 陈咪, 叶勤文, 张皋鹏. 斜裁裙参数化结构模型的构建[J]. 纺织学报, 2020, 41(07): 135-140. |
| [9] | 夏海浜, 黄鸿云, 丁佐华. 基于迁移学习与支持向量机的服装舒适度评估[J]. 纺织学报, 2020, 41(06): 125-131. |
| [10] | 潘博, 钟跃崎. 基于二维图像的三维服装重建[J]. 纺织学报, 2020, 41(04): 123-128. |
| [11] | 许倩, 陈敏之. 基于深度学习的服装丝缕平衡性评价系统[J]. 纺织学报, 2019, 40(10): 191-195. |
| [12] | 孟想 辛斌杰 李佳平. 采用多角度成像技术的纺织品三维轮廓重建算法[J]. 纺织学报, 2018, 39(04): 144-150. |
| [13] | 程杰 陈利. 利用激光扫描点云的碳纤维织物表面三维模型重建[J]. 纺织学报, 2016, 37(4): 54-59. |
|
||
 京公网安备11010502044800号
京公网安备11010502044800号