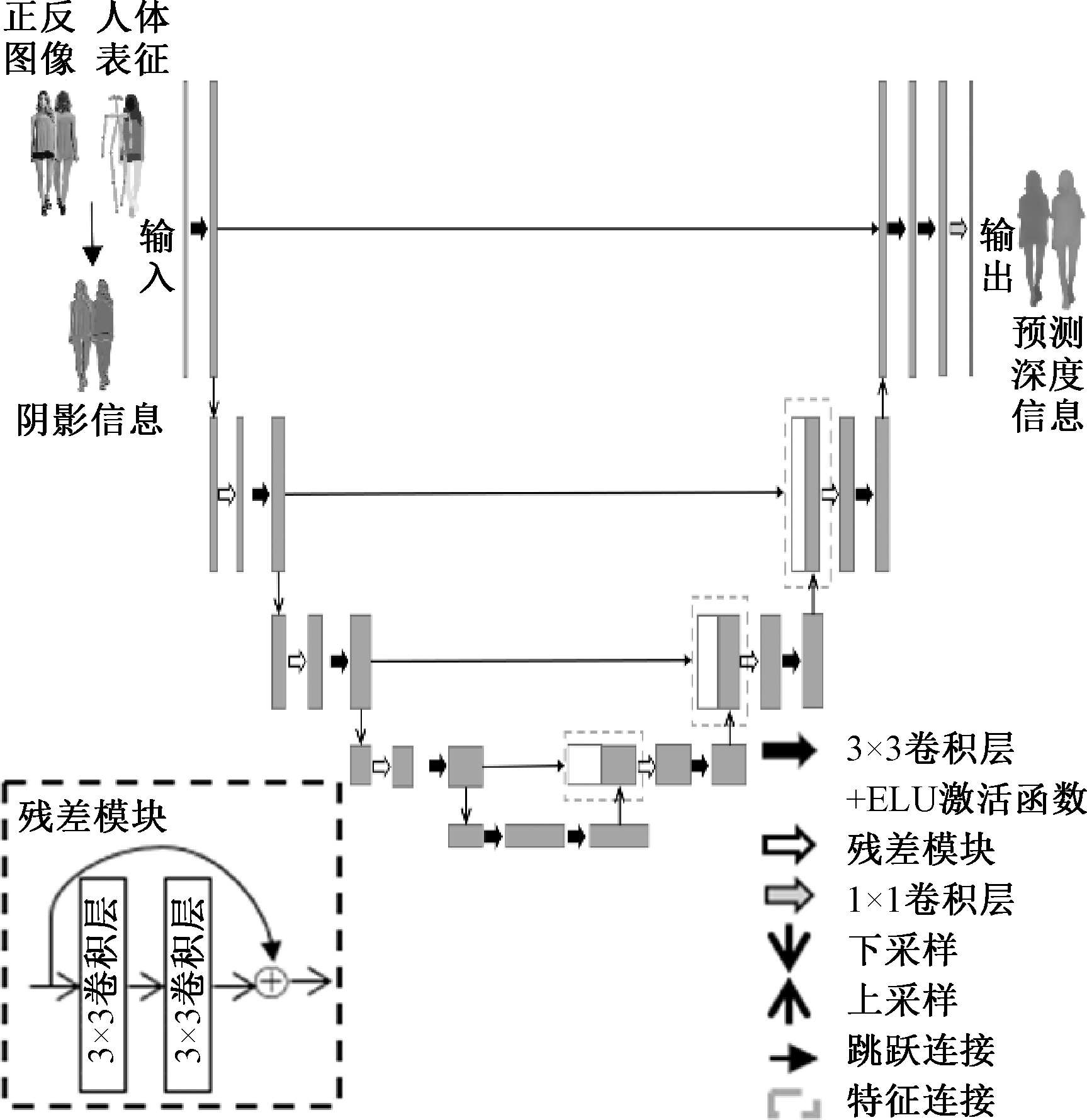
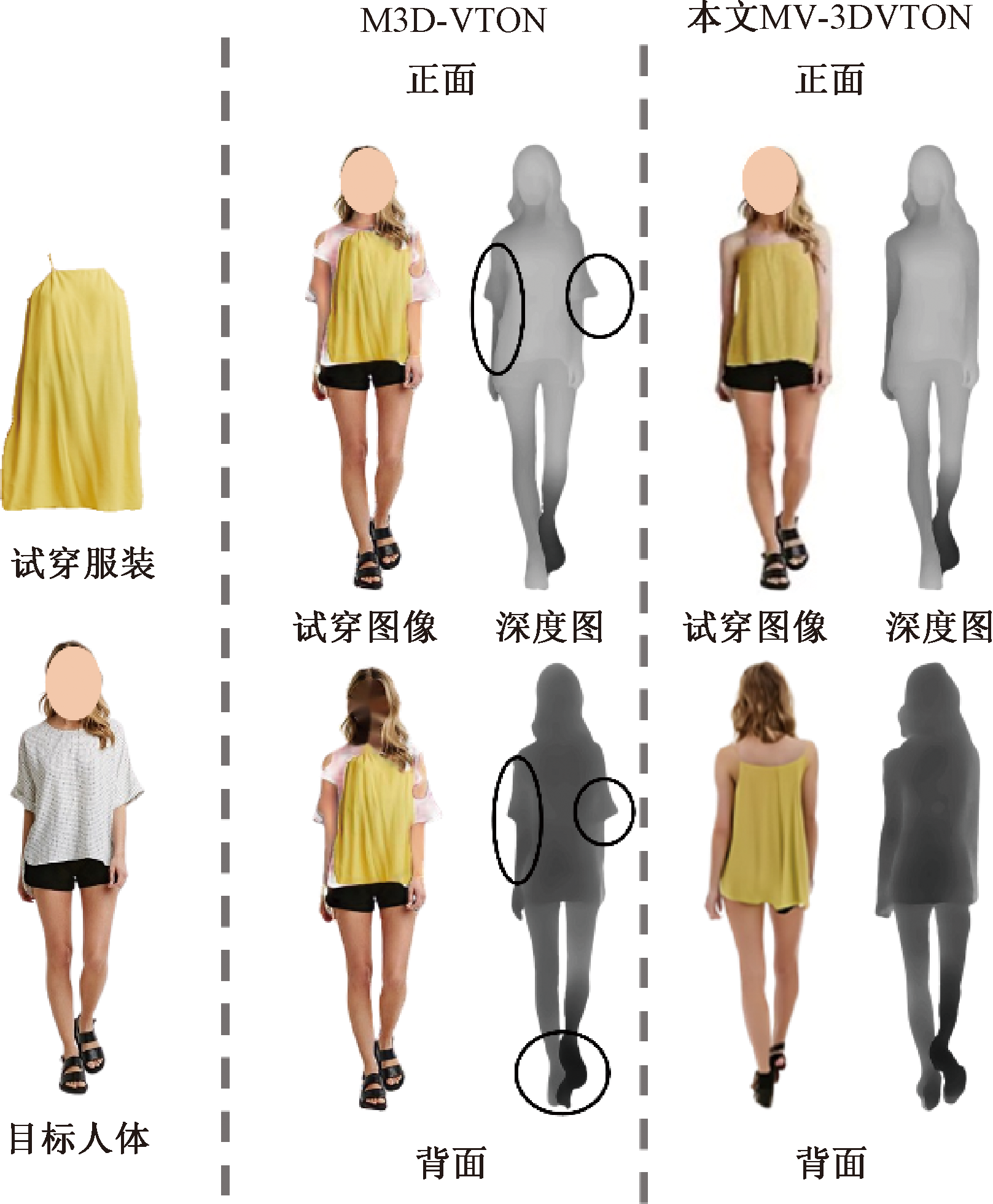
Journal of Textile Research ›› 2025, Vol. 46 ›› Issue (03): 167-176.doi: 10.13475/j.fzxb.20240503801
• Apparel Engineering • Previous Articles Next Articles
YU Haoran, WANG Ping( ), WANG Hao, DING Dong
), WANG Hao, DING Dong
CLC Number:
| [1] | 郑小虎, 刘正好, 陈峰, 等. 纺织工业智能发展现状与展望[J]. 纺织学报, 2023, 44(8): 205-216. |
| ZHENG Xiaohu, LIU Zhenghao, CHEN Feng, et al. Current status and prospect of intelligent development in textile industry[J]. Journal of Textile Research, 2023, 44(8): 205-216. | |
| [2] | 雷鸽, 李小辉. 数字化服装结构设计技术的研究进展[J]. 纺织学报, 2022, 43(4): 203-209. |
| LEI Ge, LI Xiaohui. Review of digital pattern-making technology in garment production[J]. Journal of Textile Research, 2022, 43(4): 203-209. | |
| [3] | UMETANI N, KAUFMAN D M, IGARASHI T, et al. Sensitive couture for interactive garment modeling and editing[J]. ACM Transactions on Graphics, 2011, 30(4): 1-12. |
| [4] | BARTLE A, SHEFFER A, KIM V G, et al. Physics-driven pattern adjustment for direct 3D garment editing[J]. ACM Transactions on Graphics, 2016, 35(4): 1-11. |
| [5] | 万燕, 陈林下. 基于Kinect的虚拟试衣相关技术的研究[J]. 智能计算机与应用, 2018, 8(4): 63-68. |
| WAN Yan, CHEN Linxia. Research on virtual fitting technology based on Kinect[J]. Intelligent Computer and Application, 2018, 8(4): 63-68. | |
| [6] | 黎博文, 王萍, 刘玉叶. 基于人体动态特征的三维服装虚拟试穿技术[J]. 纺织学报, 2021, 42(9): 144-149. |
| LI Bowen, WANG Ping, LIU Yuye. 3-D virtual try-on technique based on dynamic feature of body postures[J]. Journal of Textile Research, 2021, 42(9): 144-149. | |
| [7] | ZHAO F, XIE Z, KAMPFFMEYER M, et al. M3D-VTON: a monocular-to-3D virtual try-on network[C]// Proceedings of the 2021 IEEE/CVF Internation-al Conference on Computer Vision (ICCV). Piscataway: IEEE, 2021: 13239-13249. |
| [8] | 袁甜甜, 王鑫, 罗炜豪, 等. 基于注意力机制和视觉转换器的三维虚拟试衣网络[J]. 纺织学报, 2023, 44(7): 192-198. |
| YUAN Tiantian, WANG Xin, LUO Weihao, et al. Three-dimensional virtual try-on network based on attention mechanism and vision transformer[J]. Journal of Textile Research, 2023, 44(7): 192-198. | |
| [9] | HAN X, WU Z, WU Z, et al. VITON: an image-based virtual try-on network[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7543-7552. |
| [10] | WANG B, ZHENG H, LIANG X, et al. Toward characteristic-preserving image-based virtual try-on network[C]// Proceedings of the European conference on computer vision(ECCV). Berlin: Springer, 2018: 589-604. |
| [11] | RAFFIEE A, SOLLAMI M. GarmentGAN:photo-realistic adversarial fashion transfer [C]// Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR). Piscataway: IEEE, 2021: 3923-3930. |
| [12] | 刘玉叶, 王萍. 基于纹理特征学习的高精度虚拟试穿智能算法[J]. 纺织学报, 2023, 44(5): 177-183. |
| LIU Yuye, WANG Ping. High-precision intelligent algorithm for virtual fitting based on texture feature learning[J]. Journal of Textile Research, 2023, 44(5): 177-183. | |
| [13] | HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models[C]// Proceedings of the 34th Conference on Neural Information Processing Systems. San Diego: NIPS, 2020: 6840-6851. |
| [14] | WANG B, ZHENG H, LIANG X, et al. TryOnDiffusion: a tale of two UNets[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2023: 4606-4615. |
| [15] | REN Y, Yu X, CHEN J, et al. Deep image spatial transformation for person image generation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Piscataway: IEEE, 2020: 7690-7699. |
| [16] | ROY P, BHATTACHARYA S, GHOSH S, et al. Multi-scale attention guided pose transfer[J]. Pattern Recognition, 2023. DOI: 10.1016/j.patcog.2023.109315. |
| [17] | LU Y, GU B, OUYANG W, et al. LSG-GAN: latent space guided generative adversarial network for person pose transfer[J]. Knowledge-Based Systems, 2023. DOI: 10.1016/j.knosys.2023.110852. |
| [18] | KHATUN A, DENMAN S, SRIDHARAN S, et al. Pose-driven attention-guided image generation for person re-identification[J]. Pattern Recognition, 2023. DOI: 10.1016/j.patcog.2022.109246. |
| [19] | BHUNIA A K, KHAN S, CHOLAKKAL H, et al. Person image synthesis via denoising diffusion model[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Piscataway: IEEE, 2023: 5968-5976. |
| [20] | ZHU Z, HUANG T, SHI B, et al. Progressive pose attention transfer for person image gener-ation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Piscataway: IEEE, 2019: 2347-2356. |
| [21] | TANG H, BAI S, ZHANG L, et al. Xinggan for person image generation[C]// Proceedings of the European conference on computer vision(ECCV). Berlin: Springer, 2020: 717-734. |
| [22] | ZHANG P, YANG L, LAI J H, et al. Exploring dual-task correlation for pose guided person image gener-ation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Piscataway: IEEE, 2022: 7713-7722. |
| [23] | PU G, MEN Y, MAO Y, et al. Controllable person image synthesis with attribute-decomposed GAN[C]// Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence. Piscataway: IEEE, 2022: 1514-1532. |
| [24] | ZHOU X, YIN M, CHEN X, et al. Cross attention based style distribution for controllable person image synthesis[C]// Proceedings of the European conference on computer vision(ECCV). Berlin: Springer, 2022: 161-178. |
| [25] | KARRAS J, HOLYNSKI A, WANG T C, et al. Dreampose:fashion image-to-video synthesis via stable diffusion[C]// 2023 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2023: 22623-22633. |
| [26] | LIU Z, LUO P, QIU S, et al. Deepfashion:powering robust clothes recognition and retrieval with rich annotations [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway: IEEE, 2016: 1096-1104. |
| [27] | SAITO S, SIMON T, SARAGIH J, et al. Pifuhd: multilevel pixel-aligned implicit function for high-resolution 3D human digitization[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CA: IEEE Computer Society, 2020: 84-93. |
| [28] |
曹玉东, 刘海燕, 贾旭, 等. 基于深度学习的图像质量评价方法综述[J]. 计算机工程与应用, 2021, 57(23): 27-36.
doi: 10.3778/j.issn.1002-8331.2106-0228 |
|
CAO Yudong, LIU Haiyan, JIA Xu, et al. Overview of image quality assessment method based on deep learn-ing[J]. Computer Engineering and Applications, 2021, 57(23) : 27-36.
doi: 10.3778/j.issn.1002-8331.2106-0228 |
|
| [29] | EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]// Proceedings of the 27th International Conference on Neural Information Processing System. San Diego: NIPS, 2014: 2366-2374. |
| [1] | LI Bowen, WANG Ping, LIU Yuye. 3-D virtual try-on technique based on dynamic feature of body postures [J]. Journal of Textile Research, 2021, 42(09): 144-149. |
|
||