纺织学报 ›› 2025, Vol. 46 ›› Issue (06): 203-211.doi: 10.13475/j.fzxb.20241200401
罗瑞奇1, 常大顺1, 胡新荣1,2,3( ), 梁金星1,2, 彭涛1,2,3, 陈佳1,2,3, 李丽1,2,3
), 梁金星1,2, 彭涛1,2,3, 陈佳1,2,3, 李丽1,2,3
LUO Ruiqi1, CHANG Dashun1, HU Xinrong1,2,3(), LIANG Jinxing1,2, PENG Tao1,2,3, CHEN Jia1,2,3, LI Li1,2,3
摘要:
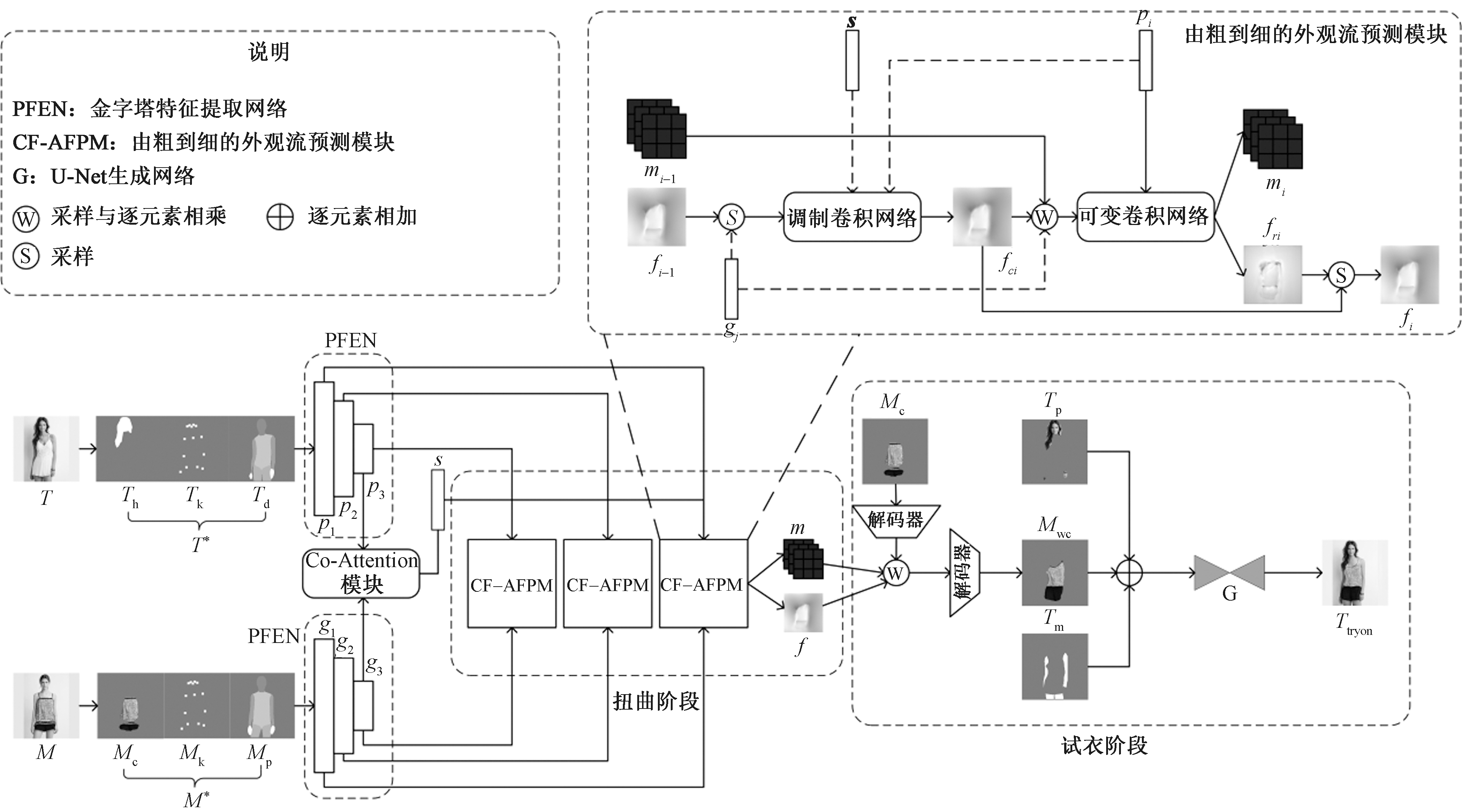
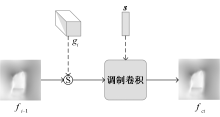
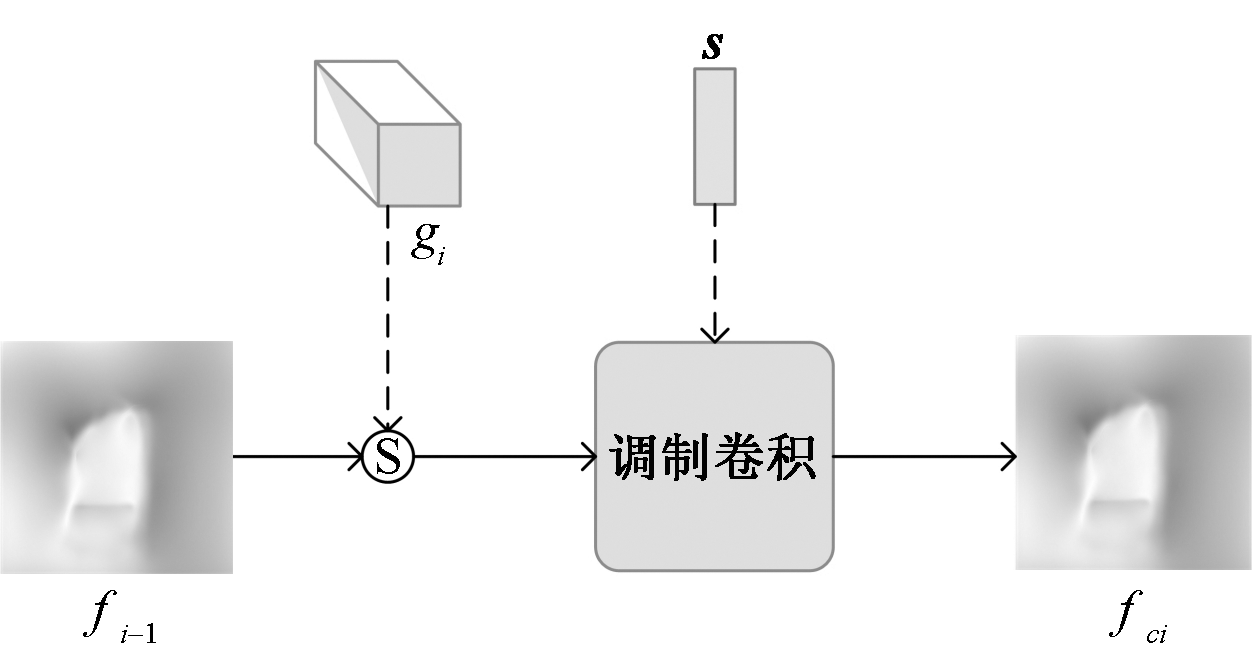
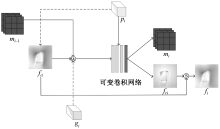
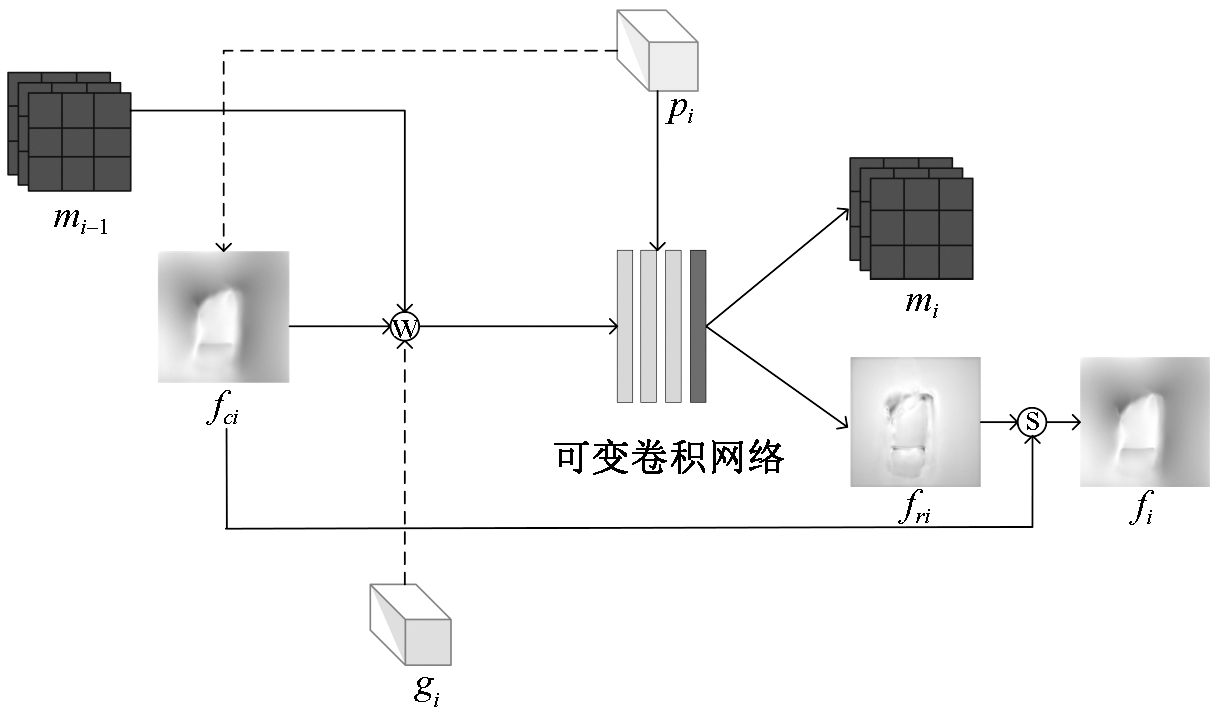
现有虚拟试衣研究大都局限于简单姿态下的单件衣物试穿,其效果依赖衣物正面图像,实际应用受限。相较而言,跨体态虚拟试衣将完整服装迁移至目标人物,实用性显著提升,但受服装与姿态影响,试穿效果面临挑战。为解决姿态差异较大时跨体态试衣效果不佳的问题,提出了一种改进外观流网络来实现跨体态虚拟试衣技术。首先,引入Co-Attention注意力模块,通过特征之间的交互强化风格向量的特征表达;其次,利用通道注意力对服装特征信息进行加权,确保重要信息得到有效传递;最后,提出了全局外观流优化模块,采用可变形卷积替换模块中的传统卷积细化流估计。结果表明,基于改进的外观流网络能够在跨体态虚拟试衣场景下实现合理的服装形变,且结构相似性指标SSIM和Frechet起始距离FID相较于FS-VTON模型分别提升了4.8%和23.5%,实现了较好的试衣效果。
中图分类号:
| [1] | HE S, SONG Y Z, XIANG T. Style-based global appearance flow for virtual try-on[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2022: 3470-3479. |
| [2] | ZHENYU X, ZAIYU H, XIN D, et al. Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Washington D.C.: IEEE Press, 2023: 23550-23559. |
| [3] | YANG H, ZHANG R, GUO X, et al. Towards photo-realistic virtual try-on by adaptively generating-preserving image content[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2020: 7850-7859. |
| [4] | WANG B, ZHENG H, LIANG X, et al. Toward characteristic-preserving image-based virtual try-on network[C]// Proceedings of the European conference on Computer Vision (ECCV). Berlin: Springer, 2018: 589-604. |
| [5] | ISSENHUTH T, MARY J, CALAUZENES C. Do not mask what you do not need to mask: a parser-free virtual try-on[C]// Proceedings of the European Conferenceon Computer Vision. Berlin: Springer, 2020: 619-635. |
| [6] | HAN X, WU Z, WU Z, et al. Viton: an image-based virtual try-on network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2018: 7543-7552. |
| [7] | DUCHON J. Splines minimizing rotation-invariant semi-norms in sobolev spaces[C]// Proceedings of a Conference on Constructive Theory of Functions of Several Variables. Berlin: Springer, 1977: 85-100. |
| [8] | HAN X, HU X, HUANG W, et al. Clothflow: a flow-based model for clothed person generation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Washington D.C.: IEEE Press, 2019: 10471-10480. |
| [9] | 韩超远, 李健, 王泽震. 改进的PF-AFN在虚拟试衣中的应用[J]. 计算机辅助设计与图形学学报, 2023, 35(10): 1500-1509. |
| HAN Chaoyuan, LI Jian, WANG Zezhen. Application of Improved PF-AFN in virtual try-on[J]. Journal of Computer-Aided Design & Computer Graphics, 2023, 35(10): 1500-1509. | |
| [10] | 陈宝玉, 张怡, 于冰冰, 等. 两阶段可调节感知蒸馏网络的虚拟试衣方法[J]. 图学学报, 2022, 43(2): 316-323. |
|
CHEN Baoyu, ZHANG Yi, YU Bingbing, et al. Two-stage adjustable perceptual distillation network for virtual try-on[J]. Journal of Graphics, 2022, 43(2): 316-323.
doi: 10.11996/JG.j.2095-302X.2022020316 |
|
| [11] |
谭泽霖, 白静, 陈冉, 等. FP-VTON:基于注意力机制的特征保持虚拟试衣网络[J]. 计算机工程与应用, 2022, 58(23): 186-196.
doi: 10.3778/j.issn.1002-8331.2105-0278 |
|
TAN Zelin, BAI Jing, CHEN Ran, et al. FP-VTON: attention-based feature preserving virtual try-on net-work[J]. Computer Engineering and Applications, 2022, 58(23): 186-196.
doi: 10.3778/j.issn.1002-8331.2105-0278 |
|
| [12] | WU Z, LIN G, TAO Q, et al. M2e-try on net: fashion from model to everyone[C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM Press, 2019: 293-301. |
| [13] | GÜLER R A, NEVEROVA N, KOKKINOS I. Densepose: dense human pose estimation in the wild[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2018: 7297-7306. |
| [14] | RAJ A, SANGKLOY P, CHANG H, et al. SwapNet: image based garment transfer[C]// Proceedings of the European Conferenceon Computer Vision. Berlin: Springer, 2018: 679-695. |
| [15] | YANG F, LIN G. CT-net: complementary transfering network for garment transfer with arbitrary geometric changes[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2021: 9899-9908. |
| [16] | DOSOVITSKIY A, FISCHER P, ILG E, et al. Flownet: learning optical flow with convolutional networks[C]// Proceedings of the IEEE International Conference on Computer Vision. Washington D.C.: IEEE Press, 2015: 2758-2766. |
| [17] | HUI T W, TANG X, LOY C C. Liteflownet: a lightweight convolutional neural network for optical flow estimation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2018: 8981-8989. |
| [18] | ILG E, MAYER N, SAIKIA T, et al. Flownet 2.0: evolution of optical flow estimation with deep net-works[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2017: 2462-2470. |
| [19] | BAI S, ZHOU H, LI Z, et al. Single stage virtual try-on via deformable attention flows[C]// European Conference on Computer Vision. Berlin: Springer, 2022: 409-425. |
| [20] | LIANG X, GONG K, SHEN X, et al. Look into person: joint body parsing & pose estimation network and a new benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4):871-885. |
| [21] | LU X, WANG W, MA C, et al. See more, know more: unsupervised video object segmentation with co-attention siamese networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2019: 3623-3632. |
| [22] |
WU J, MAZUR T R, RUAN S, et al. A deep boltzmann machine-driven level set method for heart motion tracking using cine MRI images[J]. Medical Image Analysis, 2018, 47: 68-80.
doi: S1361-8415(18)30128-2 pmid: 29679848 |
| [23] | LIU F, WANG K, LIU D, et al. Deep pyramid local attention neural network for cardiac structure segmentation in two-dimensional echocardiography[J]. Medical Image Analysis, 2021.DOI:10.1016/j.medin.2020. 101873. |
| [24] | AHN S S, TA K, THORN S L, et al. Co-attention spatial transformer network for unsupervised motion tracking and cardiac strain analysis in 3d echocardiography[J]. Medical Image Analysis, 2023.DOI:10.1016/j.media.2022.102711. |
| [25] | SUN D, ROTH S, BLACK M J. A quantitative analysis of current practices in optical flow estimation and the principles behind them[J]. International Journal of Computer Vision, 2014, 106: 115-137. |
| [26] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recogni-tion[J]. Compute Science, 2014.DOI:10.48550/arxiv.1409.1556. |
| [27] | LIU Z, LUO P, QIU S, et al. Deepfashion: powering robust clothes recognition and retrieval with rich annotations[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2016: 1096-1104. |
| [28] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [29] | HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[J]. Advances in Neural Information Processing Systems, 2017. DOI:10.48550/arxiv.1706.08500. |
| [30] | ZHANG P, ZHANG B, CHEN D, et al. Cross-domain correspondence learning for exemplar-based image translation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2020: 5143-5153. |
| [1] | 纪梦琪, 何瑛, 马咏倩. 基于三维试衣的凸肚体男西裤样板的优化[J]. 纺织学报, 2025, 46(06): 187-195. |
| [2] | 荆建伟, 胡裕鹏, 马王菲, 袁子舜, 顾冰菲, 徐望. 防弹衣间隙量与防护效果的有限元分析[J]. 纺织学报, 2025, 46(04): 187-196. |
| [3] | 侯珏, 丁焕, 杨阳, 陆寅雯, 余灵婕, 刘正. 基于混合知识蒸馏和特征增强技术的轻量级无解析式虚拟试衣网络[J]. 纺织学报, 2024, 45(09): 164-174. |
| [4] | 陆寅雯, 侯珏, 杨阳, 顾冰菲, 张宏伟, 刘正. 基于姿态嵌入机制和多尺度注意力的单张着装图像视频合成[J]. 纺织学报, 2024, 45(07): 165-172. |
| [5] | 胡旭东, 汤炜, 曾志发, 汝欣, 彭来湖, 李建强, 王博平. 基于轻量化卷积神经网络的纬编针织物组织结构分类[J]. 纺织学报, 2024, 45(05): 60-69. |
| [6] | 顾梅花, 花玮, 董晓晓, 张晓丹. 基于上下文提取与注意力融合的遮挡服装图像分割[J]. 纺织学报, 2024, 45(05): 155-164. |
| [7] | 师红宇, 位营杰, 管声启, 李怡. 基于残差结构的棉花异性纤维检测算法[J]. 纺织学报, 2023, 44(12): 35-42. |
| [8] | 马创佳, 齐立哲, 高晓飞, 王子恒, 孙云权. 基于改进YOLOv4-Tiny的缝纫线迹质量检测方法[J]. 纺织学报, 2023, 44(08): 181-188. |
| [9] | 袁甜甜, 王鑫, 罗炜豪, 梅琛楠, 韦京艳, 钟跃崎. 基于注意力机制和视觉转换器的三维虚拟试衣网络[J]. 纺织学报, 2023, 44(07): 192-198. |
| [10] | 付晗, 胡峰, 龚杰, 余联庆. 面向织物疵点检测的缺陷重构方法[J]. 纺织学报, 2023, 44(07): 103-109. |
| [11] | 叶勤文, 王朝晖, 黄荣, 刘欢欢, 万思邦. 虚拟服装迁移在个性化服装定制中的应用[J]. 纺织学报, 2023, 44(06): 183-190. |
| [12] | 陈佳, 杨聪聪, 刘军平, 何儒汉, 梁金星. 手绘草图到服装图像的跨域生成[J]. 纺织学报, 2023, 44(01): 171-178. |
| [13] | 顾梅花, 刘杰, 李立瑶, 崔琳. 结合特征学习与注意力机制的服装图像分割[J]. 纺织学报, 2022, 43(11): 163-171. |
| [14] | 鲁虹, 宋佳怡, 李圆圆, 滕峻峰. 基于合体两片袖的内旋造型结构设计[J]. 纺织学报, 2022, 43(08): 140-146. |
| [15] | 王春茹, 袁月, 曹晓梦, 范依琳, 钟安华. 立领结构参数对服装造型的影响[J]. 纺织学报, 2022, 43(03): 153-159. |
|
||
 京公网安备11010502044800号
京公网安备11010502044800号