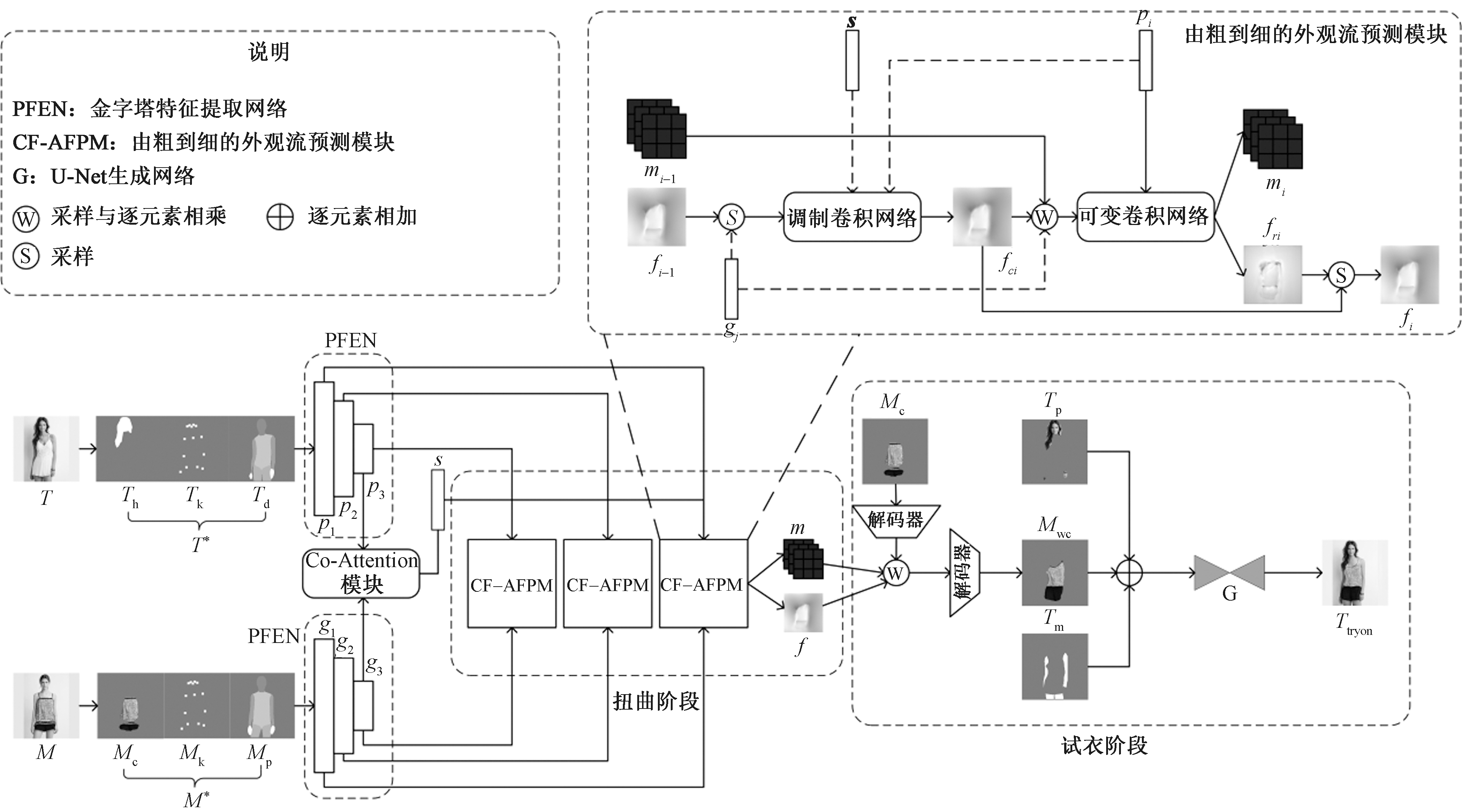
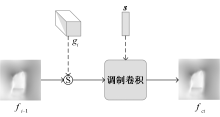
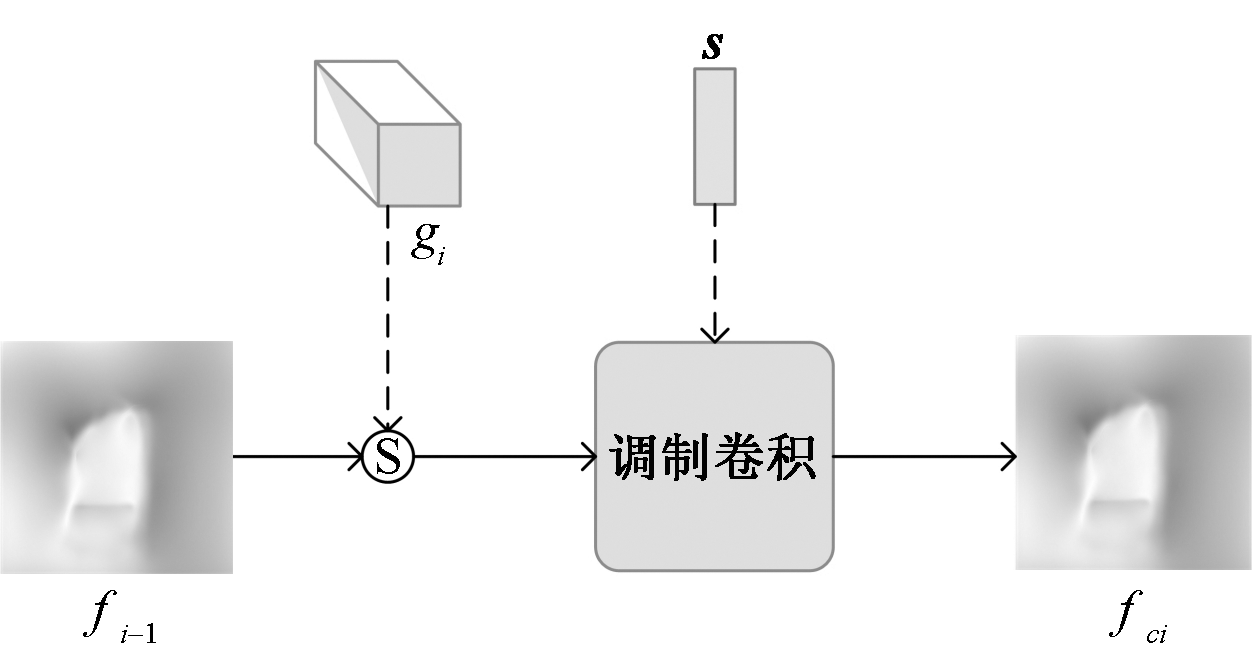
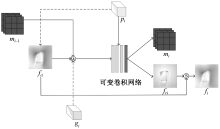
Journal of Textile Research ›› 2025, Vol. 46 ›› Issue (06): 203-211.doi: 10.13475/j.fzxb.20241200401
• Apparel Engineering • Previous Articles Next Articles
LUO Ruiqi1, CHANG Dashun1, HU Xinrong1,2,3( ), LIANG Jinxing1,2, PENG Tao1,2,3, CHEN Jia1,2,3, LI Li1,2,3
), LIANG Jinxing1,2, PENG Tao1,2,3, CHEN Jia1,2,3, LI Li1,2,3
CLC Number:
| [1] | HE S, SONG Y Z, XIANG T. Style-based global appearance flow for virtual try-on[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2022: 3470-3479. |
| [2] | ZHENYU X, ZAIYU H, XIN D, et al. Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Washington D.C.: IEEE Press, 2023: 23550-23559. |
| [3] | YANG H, ZHANG R, GUO X, et al. Towards photo-realistic virtual try-on by adaptively generating-preserving image content[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2020: 7850-7859. |
| [4] | WANG B, ZHENG H, LIANG X, et al. Toward characteristic-preserving image-based virtual try-on network[C]// Proceedings of the European conference on Computer Vision (ECCV). Berlin: Springer, 2018: 589-604. |
| [5] | ISSENHUTH T, MARY J, CALAUZENES C. Do not mask what you do not need to mask: a parser-free virtual try-on[C]// Proceedings of the European Conferenceon Computer Vision. Berlin: Springer, 2020: 619-635. |
| [6] | HAN X, WU Z, WU Z, et al. Viton: an image-based virtual try-on network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2018: 7543-7552. |
| [7] | DUCHON J. Splines minimizing rotation-invariant semi-norms in sobolev spaces[C]// Proceedings of a Conference on Constructive Theory of Functions of Several Variables. Berlin: Springer, 1977: 85-100. |
| [8] | HAN X, HU X, HUANG W, et al. Clothflow: a flow-based model for clothed person generation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Washington D.C.: IEEE Press, 2019: 10471-10480. |
| [9] | 韩超远, 李健, 王泽震. 改进的PF-AFN在虚拟试衣中的应用[J]. 计算机辅助设计与图形学学报, 2023, 35(10): 1500-1509. |
| HAN Chaoyuan, LI Jian, WANG Zezhen. Application of Improved PF-AFN in virtual try-on[J]. Journal of Computer-Aided Design & Computer Graphics, 2023, 35(10): 1500-1509. | |
| [10] | 陈宝玉, 张怡, 于冰冰, 等. 两阶段可调节感知蒸馏网络的虚拟试衣方法[J]. 图学学报, 2022, 43(2): 316-323. |
|
CHEN Baoyu, ZHANG Yi, YU Bingbing, et al. Two-stage adjustable perceptual distillation network for virtual try-on[J]. Journal of Graphics, 2022, 43(2): 316-323.
doi: 10.11996/JG.j.2095-302X.2022020316 |
|
| [11] |
谭泽霖, 白静, 陈冉, 等. FP-VTON:基于注意力机制的特征保持虚拟试衣网络[J]. 计算机工程与应用, 2022, 58(23): 186-196.
doi: 10.3778/j.issn.1002-8331.2105-0278 |
|
TAN Zelin, BAI Jing, CHEN Ran, et al. FP-VTON: attention-based feature preserving virtual try-on net-work[J]. Computer Engineering and Applications, 2022, 58(23): 186-196.
doi: 10.3778/j.issn.1002-8331.2105-0278 |
|
| [12] | WU Z, LIN G, TAO Q, et al. M2e-try on net: fashion from model to everyone[C]// Proceedings of the 27th ACM International Conference on Multimedia. New York: ACM Press, 2019: 293-301. |
| [13] | GÜLER R A, NEVEROVA N, KOKKINOS I. Densepose: dense human pose estimation in the wild[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2018: 7297-7306. |
| [14] | RAJ A, SANGKLOY P, CHANG H, et al. SwapNet: image based garment transfer[C]// Proceedings of the European Conferenceon Computer Vision. Berlin: Springer, 2018: 679-695. |
| [15] | YANG F, LIN G. CT-net: complementary transfering network for garment transfer with arbitrary geometric changes[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2021: 9899-9908. |
| [16] | DOSOVITSKIY A, FISCHER P, ILG E, et al. Flownet: learning optical flow with convolutional networks[C]// Proceedings of the IEEE International Conference on Computer Vision. Washington D.C.: IEEE Press, 2015: 2758-2766. |
| [17] | HUI T W, TANG X, LOY C C. Liteflownet: a lightweight convolutional neural network for optical flow estimation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2018: 8981-8989. |
| [18] | ILG E, MAYER N, SAIKIA T, et al. Flownet 2.0: evolution of optical flow estimation with deep net-works[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2017: 2462-2470. |
| [19] | BAI S, ZHOU H, LI Z, et al. Single stage virtual try-on via deformable attention flows[C]// European Conference on Computer Vision. Berlin: Springer, 2022: 409-425. |
| [20] | LIANG X, GONG K, SHEN X, et al. Look into person: joint body parsing & pose estimation network and a new benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4):871-885. |
| [21] | LU X, WANG W, MA C, et al. See more, know more: unsupervised video object segmentation with co-attention siamese networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2019: 3623-3632. |
| [22] |
WU J, MAZUR T R, RUAN S, et al. A deep boltzmann machine-driven level set method for heart motion tracking using cine MRI images[J]. Medical Image Analysis, 2018, 47: 68-80.
doi: S1361-8415(18)30128-2 pmid: 29679848 |
| [23] | LIU F, WANG K, LIU D, et al. Deep pyramid local attention neural network for cardiac structure segmentation in two-dimensional echocardiography[J]. Medical Image Analysis, 2021.DOI:10.1016/j.medin.2020. 101873. |
| [24] | AHN S S, TA K, THORN S L, et al. Co-attention spatial transformer network for unsupervised motion tracking and cardiac strain analysis in 3d echocardiography[J]. Medical Image Analysis, 2023.DOI:10.1016/j.media.2022.102711. |
| [25] | SUN D, ROTH S, BLACK M J. A quantitative analysis of current practices in optical flow estimation and the principles behind them[J]. International Journal of Computer Vision, 2014, 106: 115-137. |
| [26] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recogni-tion[J]. Compute Science, 2014.DOI:10.48550/arxiv.1409.1556. |
| [27] | LIU Z, LUO P, QIU S, et al. Deepfashion: powering robust clothes recognition and retrieval with rich annotations[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2016: 1096-1104. |
| [28] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [29] | HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[J]. Advances in Neural Information Processing Systems, 2017. DOI:10.48550/arxiv.1706.08500. |
| [30] | ZHANG P, ZHANG B, CHEN D, et al. Cross-domain correspondence learning for exemplar-based image translation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Washington D.C.: IEEE Press, 2020: 5143-5153. |
|
||